
Collection do Povo
Saving and growing knowledge with a hybrid annotation tool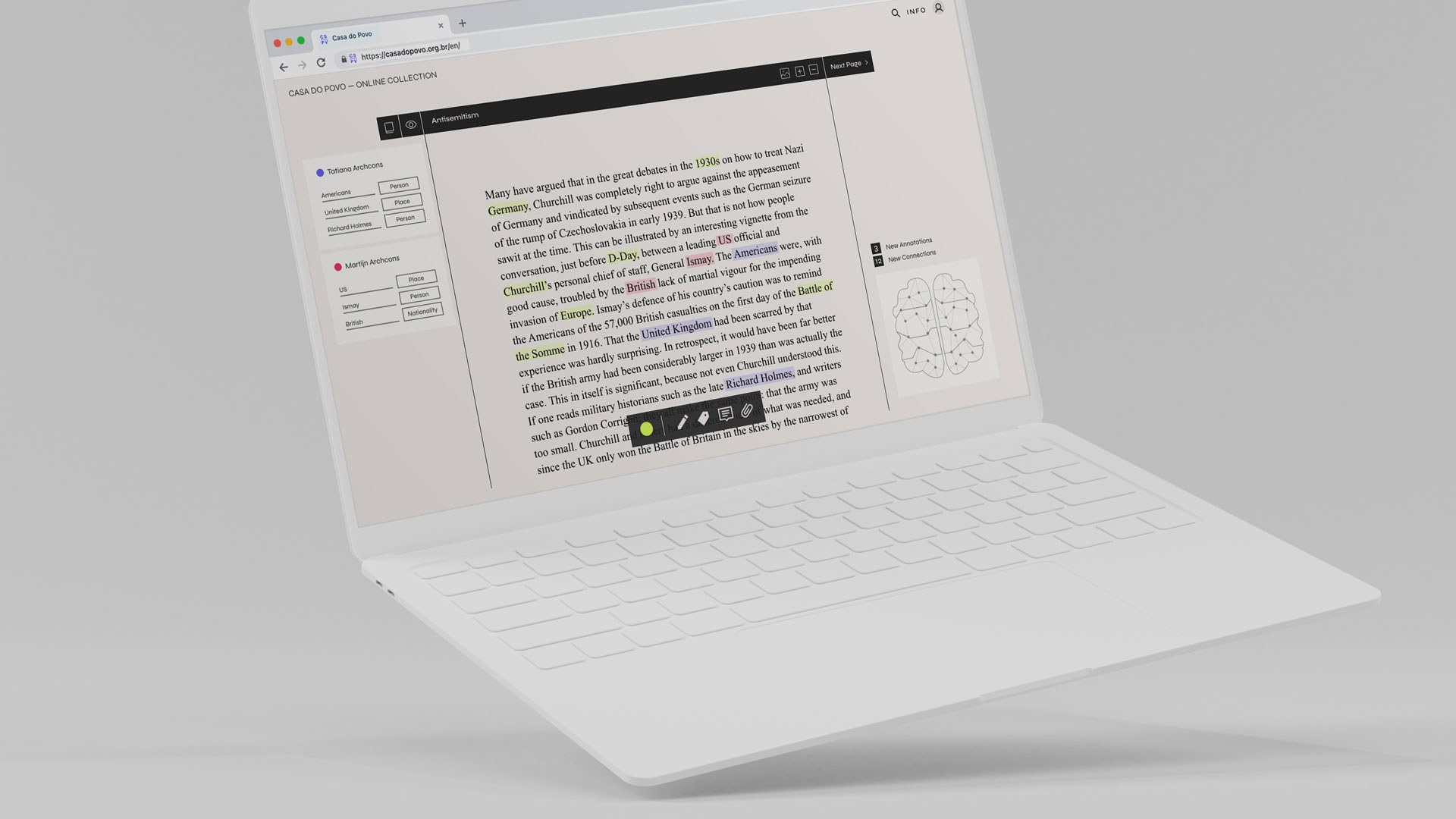
-
Client:
Archival Consciousness
- Team:
-
Disciplines:
Concept, UX/UI, Interaction Design
-
Schoolyear:
2020-2021
Libraries and archives try to save knowledge by digitizing books. But they miss to collect the emerging knowledge when readers work with texts – interpretations, notes, connections and references. Furthermore searching for the right content and understanding the context and a topics reach is difficult. A lot of knowledge stays in the dark.
Collection do povo is an online platform that enables researchers to contribute to and grow the content of a library by annotating words on book pages. These annotations create an interconnected graph of themes and topics which helps researchers to be inspired and discover correlations between books.
A bit more context...
Archival Consciousness aims to make library collections more accessible digitally by providing a flexible, rich and dynamic data environment. The goal is to design a system that , through user participation, will gradually make the collection of the library available online and will produce an overview map of the content so that researchers can easily find annotations and be inspired in their work.
For this project, we took as a use-case the library of Casa do Povo, a community centre in Brazil, which has books from Jewish immigrants who fled to the country during the Second World War.
Visualizing data that does not exist...
Our project consisted of two parts: visualizing the contents of a library and growing their content online. – We started with the first part. As we found out, almost all online libraries and archives follow the same search mechanism. Users already have to know what they are searching for and can only enter their query into a search bar. Our user interviews revealed that this is not inspiring, and it also requires a certain expertise to know the keywords of a research field. Therefore, we wanted to create an inspiring data visualization, which gives an overview of the content of a library and makes searching easier.
Our first prototype is a tree map that shows the library’s content in different sized cells representing the number of books related to a search query. The filter bar provides help in reducing the selection, and we tried to show book titles as soon as possible.
The only problem was, there was no data to fill up the topics we had used on the tree-map. So, we had to move to the second part of our project and gather data and knowledge on the available books.

Annotating texts to collect data...
As we collected the necessary data, we learned that technology can already retrieve a good amount of information with tools like optical character recognition and natural language processing (NLP). But we also experienced ourselves, that NLP is often mistaken, especially when it comes to languages that are not as common as English.
In order for us to accurately collect information about books and to connect content so that researchers can find related books, we needed human annotations.. But how do we get users to really help to grow this knowledge?
We researched the fields of motivation and crowdsourcing and found that elements used in gamification could help our case. We also looked into common annotation tools. These helped us to design an easy-to-use annotation tool that works both for personal annotations as well as for collecting data.

Three parts to a prototype
In our final result, the user is first guided through an onboarding where we stimulate motivation by addressing support for other researchers. This makes users feel related and gives them a bigger purpose for their actions.

In the annotation part, users find highlighted words that have already been recognized by NLP. By clicking on a word, they are asked a series of questions that follow a What – Who – Where – When principle. This has a tunneling effect on the user and works as a quiz. In the back those questions create connections to books that mention the same information. To reward each action, we visualize connections made in the brain and present the number of connections that have been made by just one annotation.
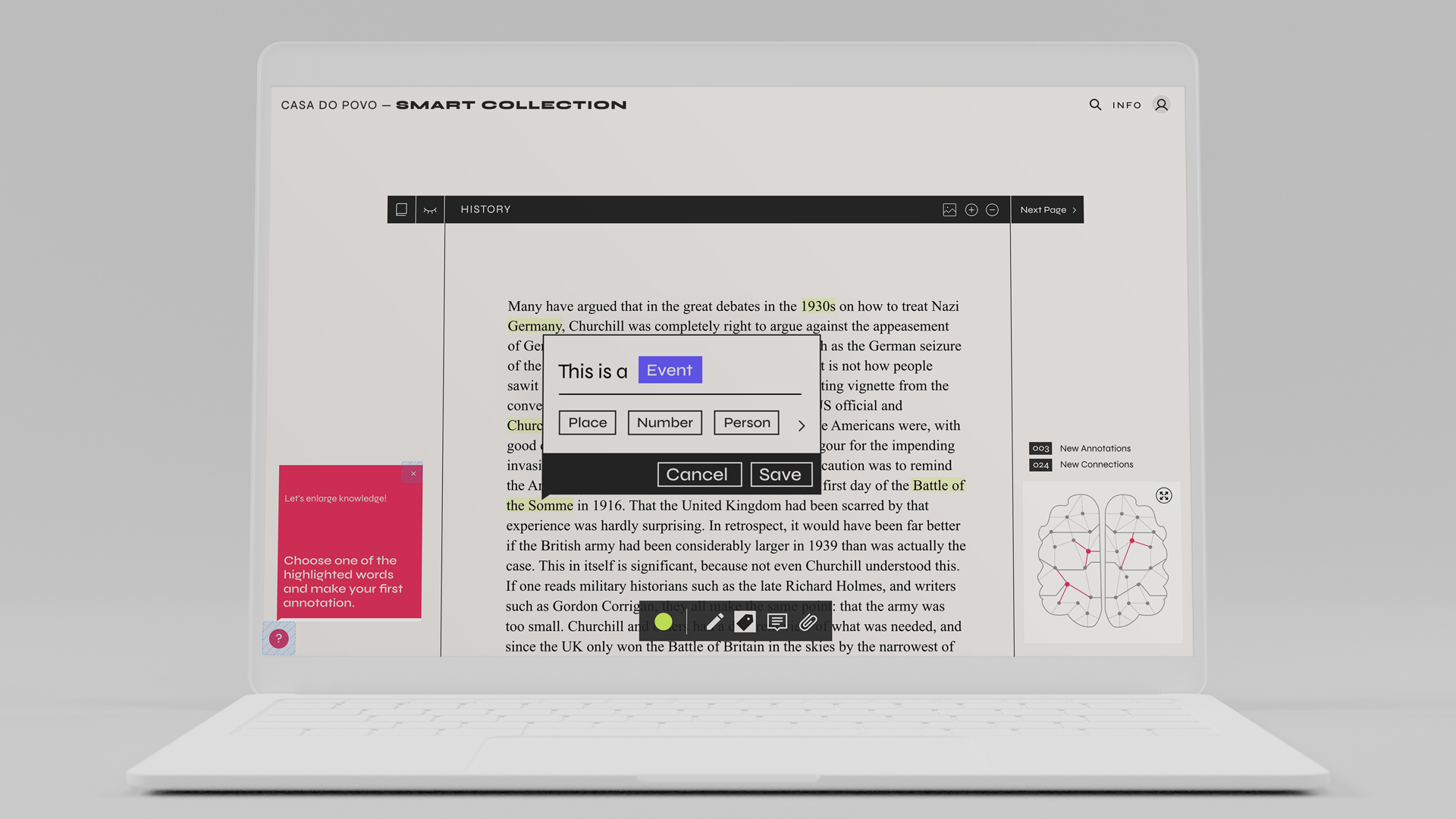
Lastly, the user can enlarge the graph and explore the content that is related to the text they annotated. This graph gives an overview of the content of the library and inspires researchers as they now have access to more information by fellow researchers and can easily navigate documents relevant to their field of interest.
Our user test showed that the structure of the platform already works well, but motivation could be stimulated even more by using the gamification element more prominently. The next steps would be to implement those insights and to create a functional data visualization of the graph.
Learn more about our final result at https://team-archcons.com
Watch the video about Collection do Povo and see how it works

